Summary
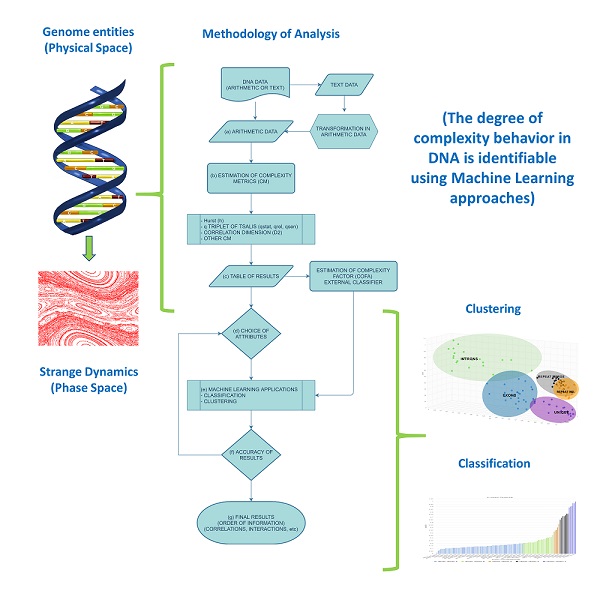
Complexity metrics and machine learning (ML) models have been utilized to analyze the lengths of segmental genomic entities of DNA sequences (exonic, intronic, intergenic, repeat, unique) with the purpose to ask questions regarding the segmental organization of the human genome within the size distribution of these sequences. For this we developed an integrated methodology that is based upon the reconstructed phase space theorem, the non-extensive statistical theory of Tsallis, ML techniques, and a technical index, integrating the generated information, which we introduce and named complexity factor (COFA). Our analysis revealed that the size distribution of the genomic regions within chromosomes are not random but follow patterns with characteristic features that have been seen through its complexity character, and it is part of the dynamics of the whole genome. Finally, this picture of dynamics in DNA is recognized using ML tools for clustering, classification, and prediction with high accuracy.
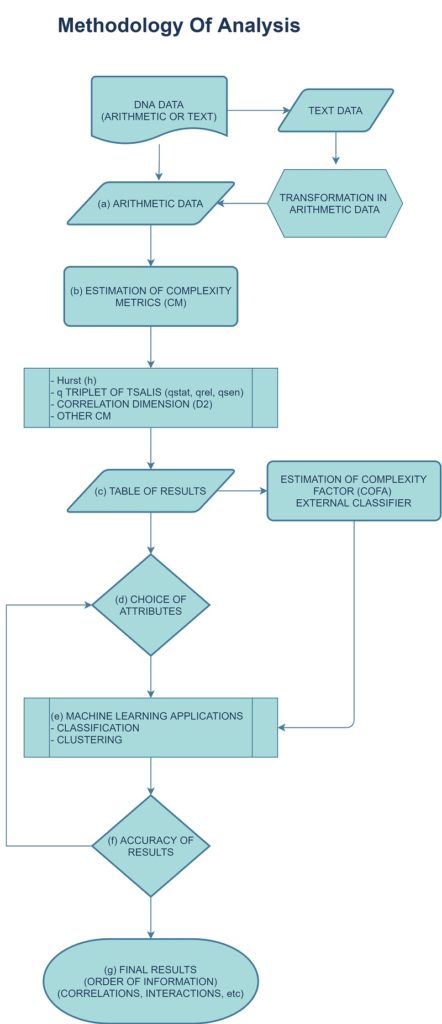
Flow Chart of Methodology of Analysis
https://doi.org/10.1016/j.isci.2021.102048